SAS gives you more flexibility to write a SAS code and create new datasets with keeping or dropping specific variables (columns) from a base dataset.
We have two SAS options DROP= and KEEP= which we can use to have more controls on column level while reading and creating sas datasets.
Things will be more clear with the following examples.
DROP Variables from a SAS Data set
Let’s take an example of the dataset sashelp.CARS which has multiple variables (or columns) such as Model, type, Origin, MSRP, Invoice, and so on. You want to create a new dataset named NEW_CARS without variables MSRP and Invoice.
You can easily drop those columns using the DROP option available in SAS data step. There are two ways you can use drop= option.
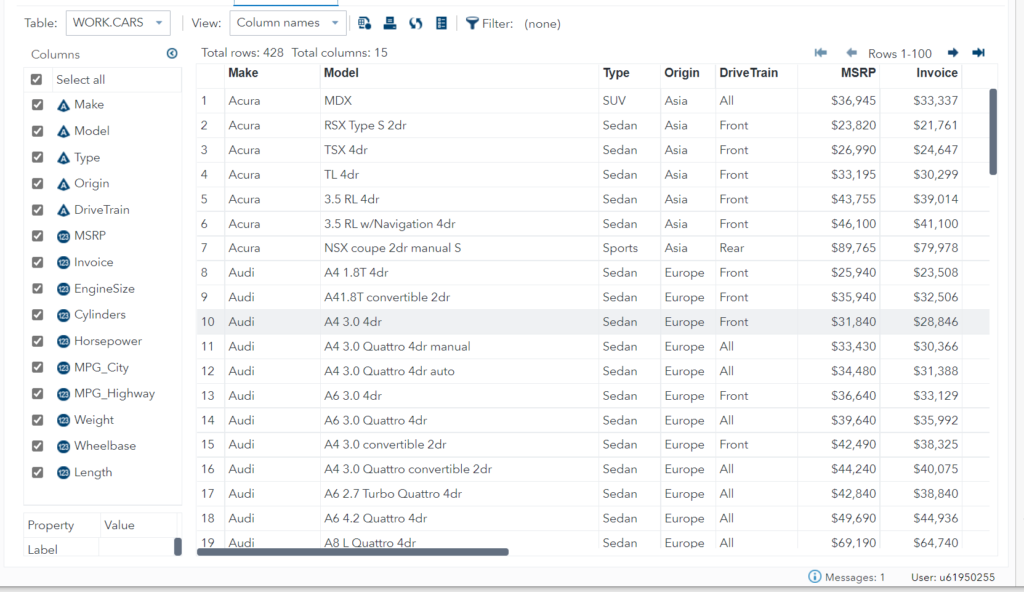
#1 Apply DROP= on target (new) table
This method is quite slow because SAS first reads all the data for all the columns from the source table and drops the mentioned columns while writing into a new data set.
data NEW_CARS(DROP=MSRP Invoice);
set sashelp.cars;
run;
#2 Apply DROP= at source table
This is a much faster way to drop specific variables and load data into the final data set as SAS doesn’t read column data from the source table itself which are mentioned in DROP= option.
data NEW_CARS;
set sashelp.cars(DROP=MSRP Invoice);
run;
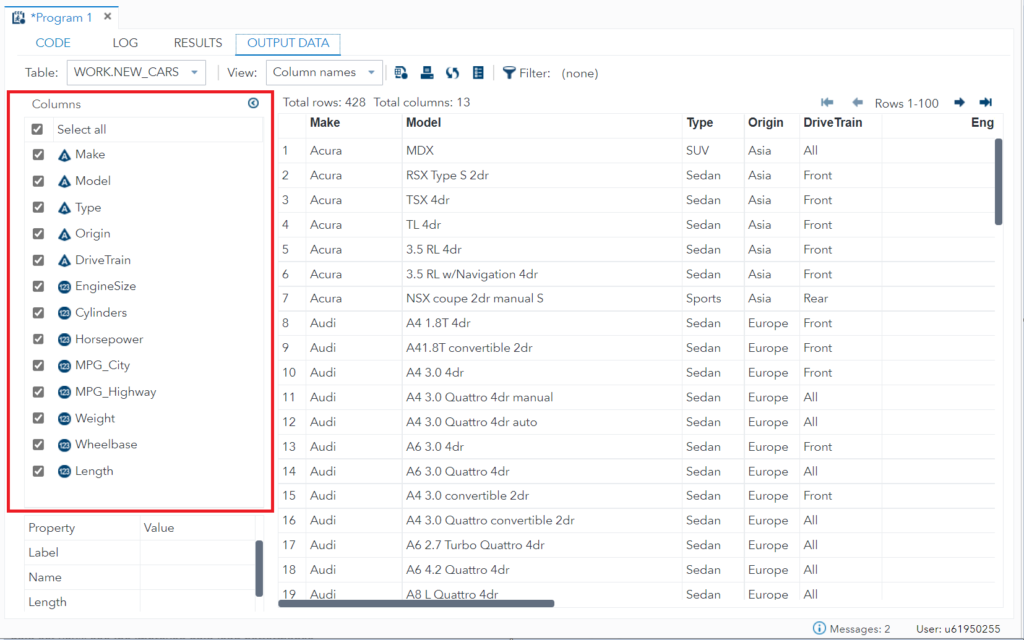
Important note:
Both the above methods produce the same results. The only thing is, the second method is way faster than the 1st one. You might not realize it now but when you’re dealing with a huge data set you’ll see the improved data load performance.
KEEP Variables from a SAS Data set
Instead of focusing on dropping variables it is always good to put more focus on what is required for you from that data set.
There might be 100s of variables available on a given data set but if you are interested to read only a few variables then the KEEP= option is very effective.
For example, from the sashelp.cars data set you want to read only Model and Origin variables. Here is an example how you can use the KEEP= option to drop variables in sas dataset and only keep what is required.
#1 Apply KEEP= on target (new) table
This method is quite slow because SAS first reads all the data for all the columns from the source table and keeps the mentioned columns and drops the rest while writing into a new data set.
data NEW_CARS(KEEP=Model Origin);
set sashelp.cars;
run;
#2 Apply KEEP= at source table
This is a much faster way to keep specific variables and load data into the final data set as SAS doesn’t read column data from the source table itself which are not mentioned in the KEEP= option.
data NEW_CARS;
set sashelp.cars(KEEP=Model Origin);
run;
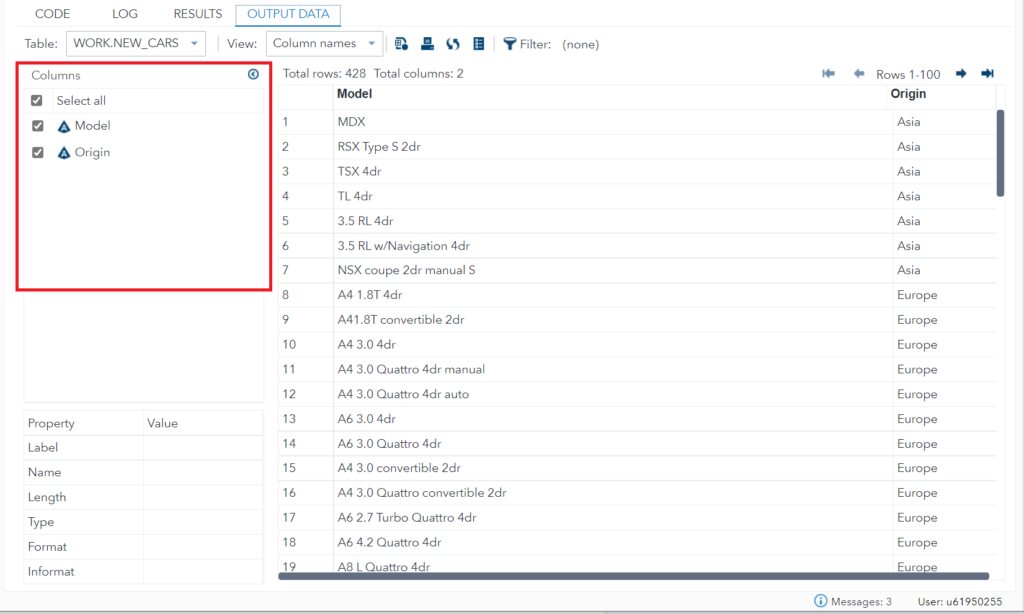
Important note:
Both the above methods produce the same results. The only thing is, the second method is way faster than the 1st one. It doesn’t matter when you’re working on small datasets but when it comes to a huge dataset, you might need to consider option 2 to optimize your query for quick load.
FAQ
You can use SAS options DROP= or even you can use KEEP= to drop specific variables from a SAS Data set. It is effective when you use it in SAS Data Step.
You can drop rest of the variables by using KEEP option along with specifying variables you want to keep it in SAS Data set. It is been used in the SAS Data Step more often.