The both nodupkey and nodup (noduprecs) options can be used in the proc sort procedure.
The function of these two options seems similar but it isn’t.
In general they remove duplicate rows but in a bit different manner. It’s very important know the difference before you try to delete duplicate rows.
- With nodupkey option SAS deletes duplicate rows based on variables specified in the BY statement.
- Whereas, with nodup or noduprecs option SAS deletes duplicate rows grouping data based on variables specified in the BY statement and then delete rows comparing all the variables present in the dataset with the previous observation.
The following example dataset demonstrate both the options with different out datasets.
/* create sas dataset */
data Employee;
input ID var;
datalines;
1 100
1 200
1 100
2 400
2 400
2 500
3 700
3 700
3 700
1 800
;
run;
/* view dataset */
proc print data=Employee;
title 'Sample Employee Dataset';
run;
NODUPKEY
The NODUPKEY option checks for and eliminates observations with duplicate BY variable values.
If you specify this option, PROC SORT compares all BY variable values for each observation to those for the previous observation written to the output data set.
If an exact match using the BY variable values is found, the observation is not written to the output data set.
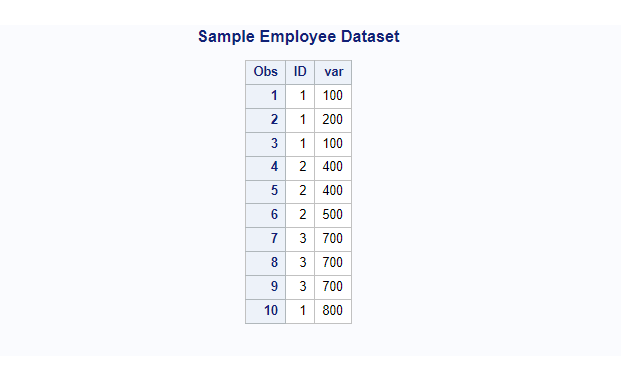
In the following example you can see how duplicate rows are being deleted with nodupkey option in proc sort.
- The out= creates a new dataset “Employee_nodupkey” after deleting the duplicates.
- The dupout= creates a new dataset “dup_data” with deleted duplicate rows which can be used further for analysis.
/* proc sort to identify and remove duplicate rows */
proc sort data=Employee out=Employee_nodupkey nodupkey dupout=dup_data;
by ID;
run;
/*view sorted dataset without duplicate rows*/
proc print data=Employee_nodupkey;
title 'Nodupkey: sorted dataset with no duplicates';
title2 'work.Employee_nodupkey';
run;
/*view duplicate data*/
proc print data=dup_data;
title 'Nodupkey: deleted duplicate rows';
title2 'work.dup_data';
run;
NODUP (NODUPRECS)
The NODUP option checks for and eliminates duplicate observations.
If you specify this option, PROC SORT compares all variable values for each observation to those for the previous observation that was written to the output data set.
If an exact match is found, the observation is not written to the output data set.
In the following example you can see how duplicate rows are being deleted with nodup(noduprecs) option in the proc sort.
- The out= creates a new dataset “Employee_nodup” after deleting the duplicates.
- The dupout= creates a new dataset “dup_data” with deleted duplicate rows which can be used further for analysis.
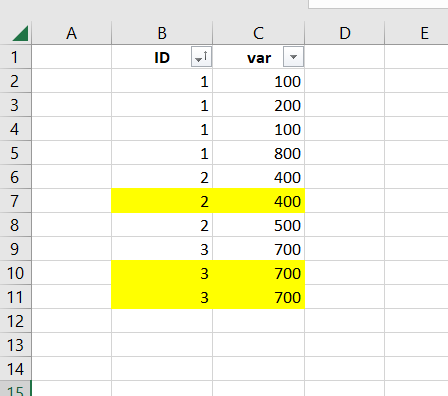
If you see the output nodup option group the data based on sorted ID values – the variable specified in the BY statement and then delete rows comparing all the variables present in the dataset with the previous observation.
The easiest way to visualize this through the below excel sheet.
- sorts the data on BY variable
- groups the data on BY variable
- compare with previous observation considering all the variables and keeps only first row.
In this example yellow highlighted observations will be deleted.
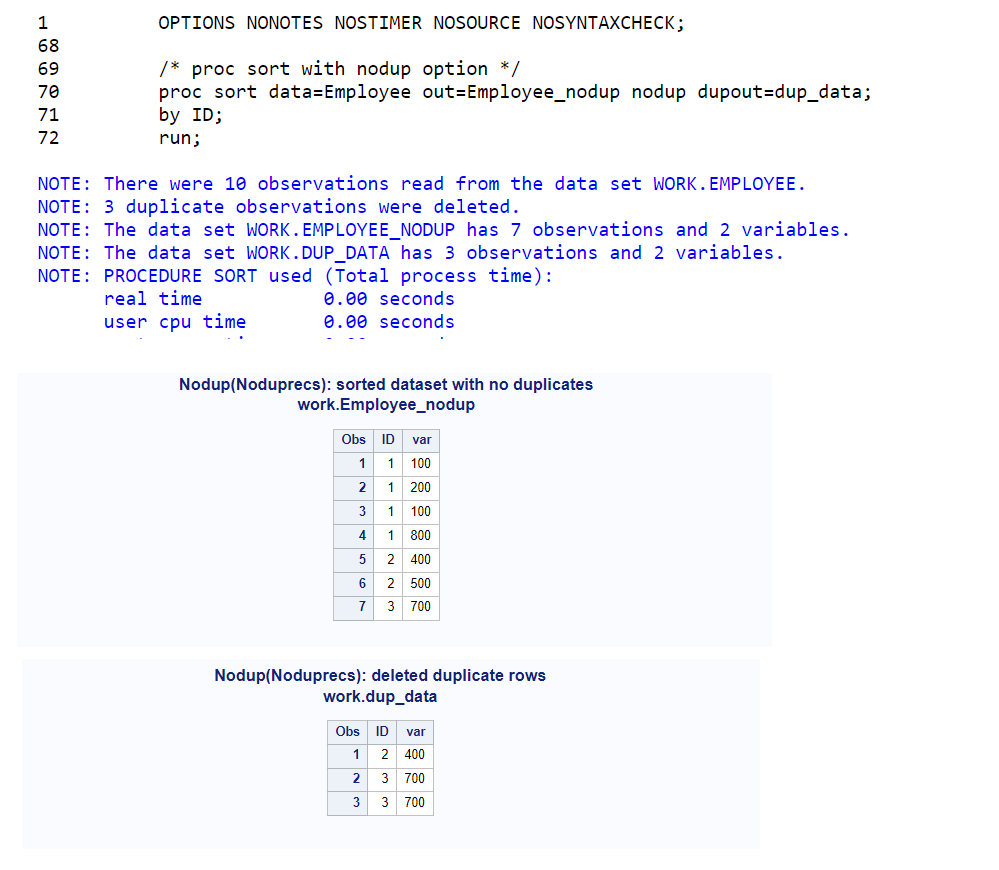
/* proc sort with nodup option */
proc sort data=Employee out=Employee_nodup nodup dupout=dup_data;
by ID;
run;
/*view sorted dataset without duplicate rows*/
proc print data=Employee_nodup;
title 'Nodup(Noduprecs): sorted dataset with no duplicates';
title2 'work.Employee_nodup';
run;
/*view duplicate data*/
proc print data=dup_data;
title 'Nodup(Noduprecs): deleted duplicate rows';
title2 'work.dup_data';
run;
I have written a separate article on how to use PROC SORT procedure with 10+ different examples that demonstrates multiple ways to use proc sort.
FAQ
NODUPKEY and NODUP are options in the PROC SORT statement in SAS used to remove duplicate observations. NODUPKEY removes consecutive duplicate observations based on the BY variables, while NODUP removes all duplicates based on the BY variables, keeping only the first occurrence. The choice between these options depends on the specific requirements of your data analysis.
To use NODUPKEY or NODUP in PROC SORT, include the respective option in the PROC SORT statement. For example, to remove consecutive duplicates, use NODUPKEY:
proc sort data=dataset_name out=sorted_dataset nodupkey;
by variable_name;
run;
To remove all duplicates, use NODUP:
proc sort data=dataset_name out=sorted_dataset nodup;
by variable_name;
run;
Yes, you can use multiple variables with NODUPKEY and NODUP options in PROC SORT. Simply list the variables within the BY statement.