In this article you’ll learn how to use the proc sort procedure in detail with 10+ examples.
The proc sort procedure in SAS used to order the observations based on one or more variables.
Furthermore, the proc sort can be used to remove duplicate observations from SAS dataset. The SORT procedure either replaces the original dataset or creates a new dataset
The PROC SORT Procedure
Syntax:
/* sas proc sort syntax */
proc sort data=<dataset> <other options>;
by <variable-1 variable-2 ...>;
run;
Example 1: The PROC SORT On A Numeric Variable
The following simple example demonstrates how to use proc sort to order sequence numbers from the given dataset.
/* create a new dataset */
data number;
input sequence 8.;
datalines;
1
20
5
10
25
15
35
50
40
45
;
run;
proc print data=number; quit;
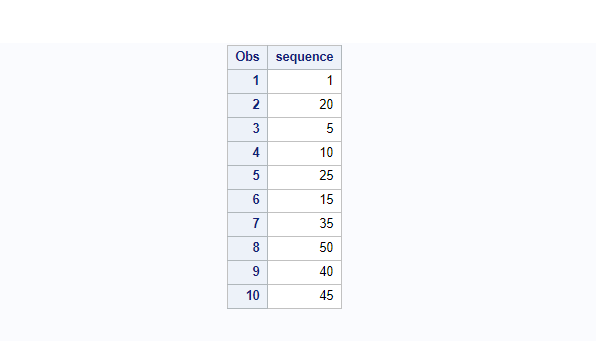
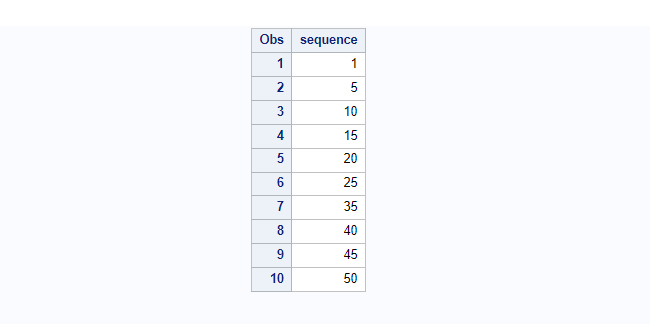
The values present on a “sequence” variable are random in nature. In order to sort it in the sequential order you can use proc sort with by variable “sequence”.
/* sort values by sequence variable */
proc sort data=number;
by sequence;
run;
/* view sorted dataset */
proc print data=number; run;
Example 2: The PROC SORT On A Char Variable
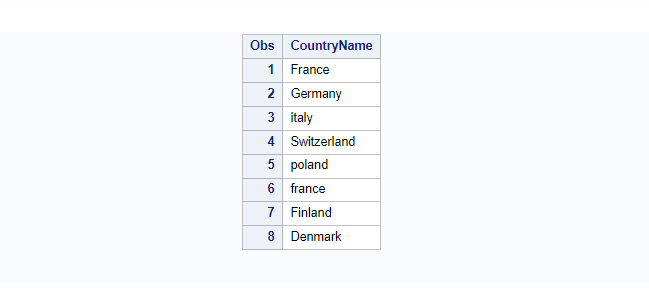
The following example demonstrates how to sort data on character variables. In this example a sample dataset “work.europe” created with a CountryName as a char variable.
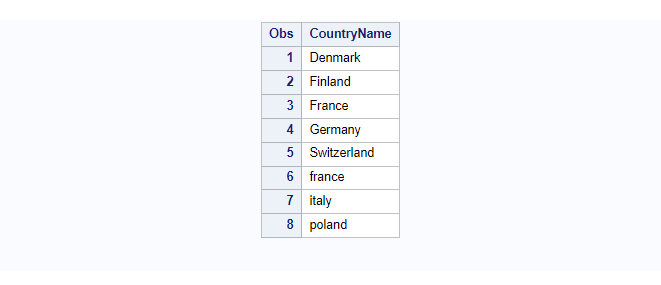
The proc sort has applied on this dataset based on CountryName. By default the proc sort procedure sorts the data first by uppercase followed by lowercase. You can observe the below example: before and after proc sort on countryname.
/* create a new dataset */
data europe;
input CountryName $1-30;
datalines;
France
Germany
italy
Switzerland
poland
france
Finland
Denmark
;
run;
/* view dataset */
proc print data=europe; run;
/* By default proc sort procedure sorts the data
first by uppercase followed by the lowercase */
proc sort data=europe;
by countryname;
run;
/* view sorted dataset */
proc print data=europe; run;
Example 3: Sorting Data Alphabetically(Ignoring the case of the letters) using sortseq=LINGUISTIC option
By default proc sort does the sorting based on uppercase followed by lowercase. The sortseq=linguistic option can be used to sort data alphabetically without considering the case of the letters.
/* sort the entire data alphabetically ignoring the case of the
letters using sortseq=LINGUISTIC option */
/* proc sort alphabetically */
proc sort data=europe sortseq=linguistic;
by countryname;
run;
/* view sorted dataset */
proc print data=europe; run;
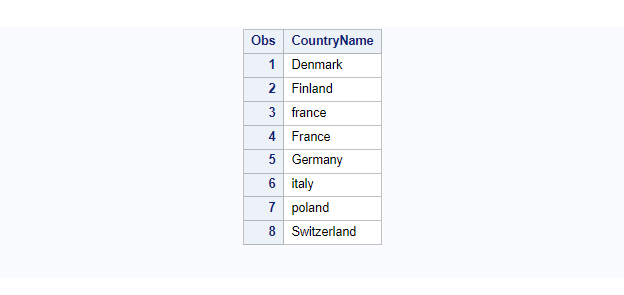
Example 4: Sorting Data Alphabetically(UpperCase, then LowerCase) using sortseq=LINGUISTIC (CASE_FIRST=UPPER)
The LINGUISTIC option can be used to sort data according to various rules. For example, if required, CASE_FIRST=UPPER rule will allow you to sort the data alphabetically by uppercase first, and then by lowercase.
If you observe carefully, group sorting is done based on uppercase first, and then lowercase.
/* sort the data alphabetically with sortseq=linguistic
(CASE_FIRST=UPPER) options */
proc sort data=europe sortseq=linguistic(CASE_FIRST=UPPER);
by CountryName;
run;
/* view sorted dataset */
proc print data=europe;run;
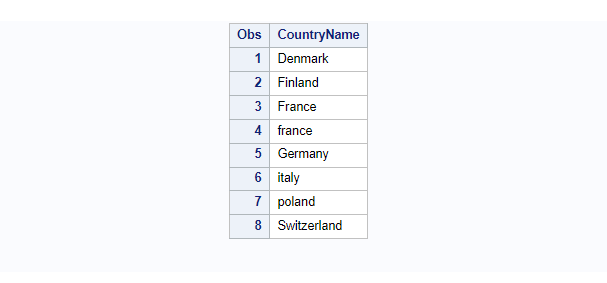
Example 5. DEFAULT: Sort Character Data That Contains Numbers
The proc sort can be used to sort the character data values that contain numbers a bit differently. First, we will see the default proc sort on char variable.
/* create a new dataset */
data days;
input dayCount $1-15;
datalines;
Day_30
Day_8
Day_3
Day_5
Day_6
;
run;
/* default sorting on char variable that contains numeric values*/
proc sort data=days; by dayCount;
run;
/* view dataset */
proc print data=days; run;
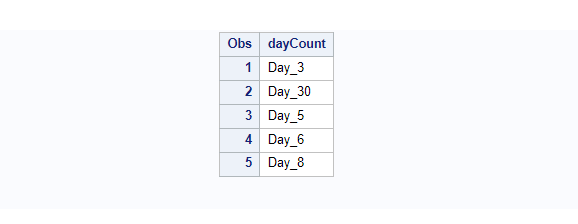
Example 6. Sort Character Data That Contains Numbers Using NUMERIC_COLLATION Option
The above work.days dataset contains a char variable dayCount where you can see numbers are also there attached with the char data. Use the NUMERIC_COLLATION=ON option with sortseq=linguistic to sort character data based on numbers present on a char data.
Sort data considering numbers present in the character values.
/* sort with NUMERIC_COLLATION option */
proc sort data=days sortseq=linguistic(NUMERIC_COLLATION=ON);
by dayCount;
run;
/* view sorted data */
proc print data=days; run;
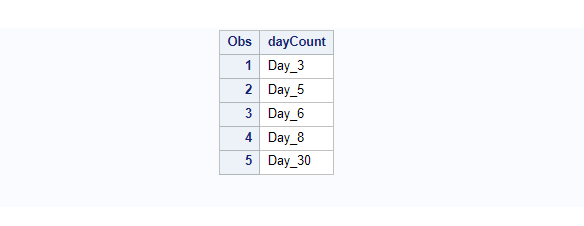
Now you can compare the sorted data from example 5 and 6. You’ll find the key difference. This method is very effective when you have character data with meaningful numeric values that can be used to sort the dataset.
Example 7. Sort Data With Special Characters That Contains Numbers Using ALTERNATE_HANDLING Option
The previous example looks like an ideal case but not necessarily you’ll deal with the same scenario.
You might have the data that contains special characters and you want to ignore those characters and sort the data based on numbers present on the char data.
/* create a new dataset */
data sasblog;
input name $1-20;
datalines;
learn%sas code
learn sascode
learn sascode2
learnsascode3
learn sas code 1
learn#sas code2
learn sas code 4
;
run;
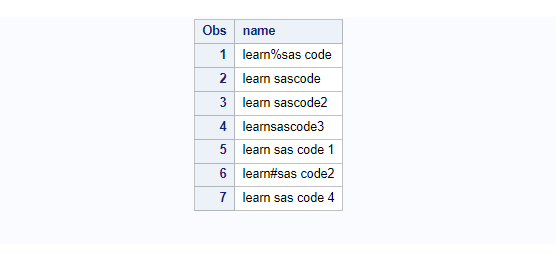
The work.sasblog dataset has a char variable “name” where you can see words are separated by special characters such as spaces, %, and #.
You can handle this scenario and sort data considering numbers which are attached to the char values.
This is how SAS by default sort the data on character variable “name” without any other options specified.
/* default sorting on char variable */
proc sort data=sasblog;
by name;
run;
/* view sorted dataset */
proc print data=sasblog;
run;
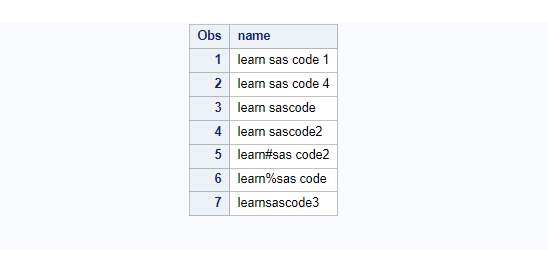
Let’s sort the data by considering numerical values along with some special characters present on the “name” variable. The ALTERNATE_HANDLING=SHIFTED option kind of suppresses the special characters and sorts the data.
/* sorting with ALTERNATE_HANDLING=SHIFTED option */
proc sort data=sasblog sortseq=linguistic(ALTERNATE_HANDLING=SHIFTED);
by name;
run;
/* view sorted dataset */
proc print data=sasblog; run;

Example 8. Create OUTPUT Dataset Using PROC SORT
If you have observed in the previous examples whenever you use proc sort, it does the sorting on the original dataset.
In case if you don’t want to modify anything on the original dataset but want to create a new dataset with sorted values out=<dataset name> option can be used.
To demonstrate this example lets create a new SAS dataset called as Employee
/* create input SAS dataset */
data Employee;
input Emp_ID 4. Emp_Name $ Dept $;
datalines;
1011 Jan Sales
1012 John Finance
1016 Gill Sales
1025 Harry Admin
1018 Harry Admin
1030 Mary Finance
1031 Peter Finance
1030 Mary Finance
1041 Tomy Admin
;
run;
/* view dataset */
proc print data=Employee; run;
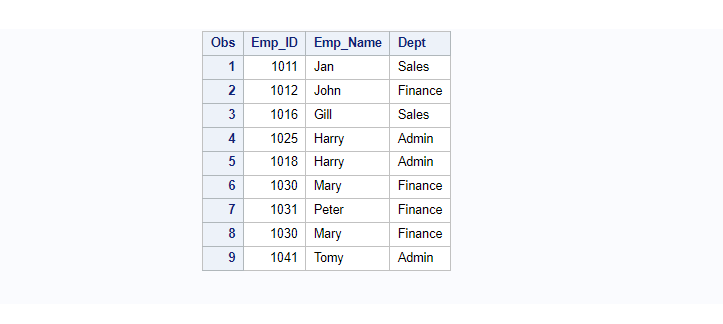
Sort The Data by Emp_ID and Create A New Dataset
The work.Employee dataset can be sorted on employee id without actually modifying it on original data work.Employee but the sorted data can be stored in the new dataset.
So, here a new dataset “Employee_sorted” will be created using the proc sort procedure.
/*sort by Emp_ID ascending*/
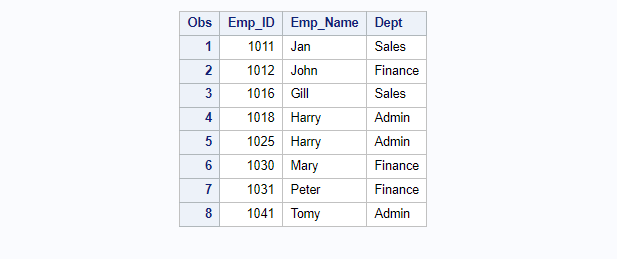
proc sort data=Employee out=Employee_sorted;
by Emp_ID;
run;
/*view sorted dataset*/
proc print data=Employee_sorted;run;
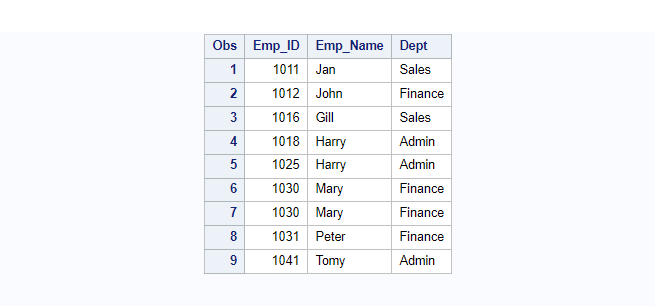
Sort data in descending order:
/* Sort Observations Descending */
/*sort by Emp_ID descending*/
proc sort data=Employee out=Employee_sorted;
by descending Emp_ID;
run;
/*view sorted dataset*/
proc print data=Employee_sorted;run;
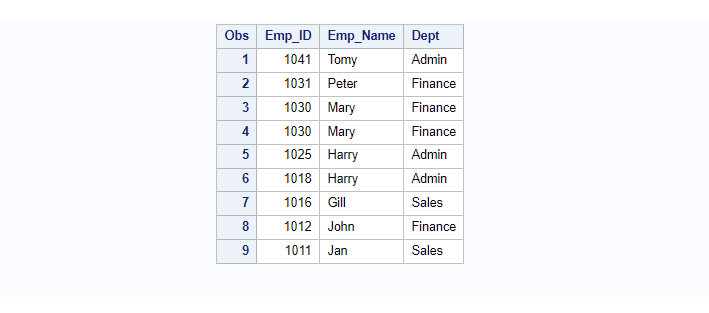
Example 9. Sort Data by Multiple Columns
Sorting on the SAS dataset can be done using multiple columns as well. You just need to specify column names on which you want to sort the data after the BY statement.
/* Sort Observations by Multiple Columns */
/*sort by Emp_ID and Emp_Name */
proc sort data=Employee out=Employee_sorted;
by Emp_ID Emp_Name;
run;
/*view sorted dataset*/
proc print data=Employee_sorted;run;
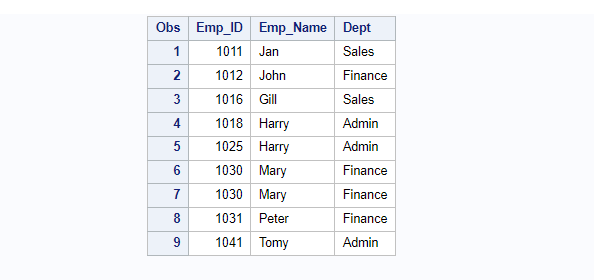
Example 10. Sort Data by ALL The Columns
You could actually sort the entire dataset considering all the columns available on that dataset.
The output either can be overwritten in the original dataset or a new dataset can be created. Instead of listing all the column names after by statement you can simply use _ALL_. SAS internally lists all the columns available on that dataset.
In this example we are creating a new dataset called work.Employee_sorted.
/* Sort Observations by all Columns */
/*proc sort by all columns */
proc sort data=Employee out=Employee_sorted;
by _all_;
run;
/*view sorted dataset*/
proc print data=Employee_sorted;run;
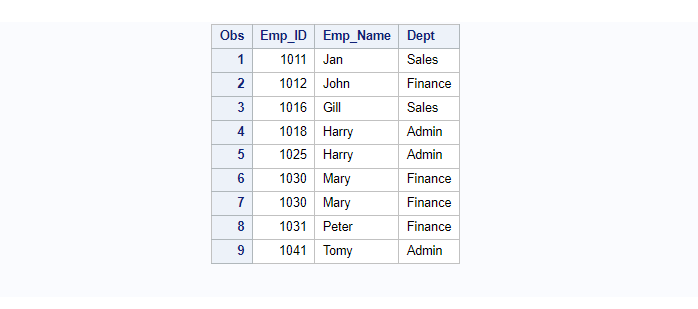
*Example 11. Use PROC SORT Procedure To Identify and Removes Duplicate Rows
The nodupkey can be used to check for and eliminate observations with duplicate BY values. You MUST use the OUT=<dataset name> option in order to avoid modifying the original dataset. A new dataset can be created without duplicates.
Also, If you want to extract what are those duplicate values then the NODUP= <dataset name> option can be used. It creates a new dataset and stores the duplicate rows there.
The following example demonstrates how to identify and remove duplicate rows based on the BY variable “Emp_ID”.
The proc sort procedure with nodupkey keeps the first row and deletes the rest of the duplicate rows.
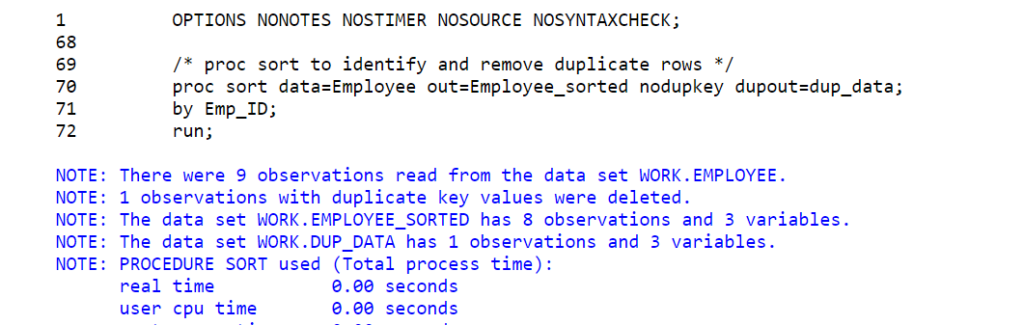
/* proc sort to identify and remove duplicate rows */
proc sort data=Employee data=Employee_sorted nodupkey dupout=dup_data;
by Emp_ID;
run;
/*view duplicate data*/
proc print data=dup_data;
run;

/*view sorted dataset without duplicate rows*/
proc print data=Employee_sorted;
run;
PLEASE NOTE: If you don’t use the OUT=<dataset name> option then the proc sort procedure removes duplicates from the original dataset.
FAQ
The PROC SORT is a SAS procedure used to sort datasets based on one or more variables. It arranges the data in ascending or descending order, making it easier to analyze and process datasets efficiently.
In PROC SORT, you specify sorting criteria using the BY statement followed by the variable names based on which you want to sort the data.
You can sort by multiple variables by listing them within the BY statement.
For example:
proc sort data=dataset_name out=sorted_dataset;
by variable1 variable2;
run;
Yes, PROC SORT can sort data in descending order. To sort data in descending order, you can use the DESCENDING option within the BY statement.
Both NODUPKEY and NODUP are options in the PROC SORT statement used to remove duplicate observations based on the variables specified in the BY statement.