One of the most common activities and issues in data management is to deal with the duplicate rows. Your well established ETL processes might be executing for weeks or months but at some point it may fail due to duplicates.
It can either be generated due to fault at source end or wrong logic written in your ETL processes.
The proc sort procedure can be used to find and delete duplicates in SAS but that’s not the only way. There are two more ways you could easily find the duplicate data and remove it from the dataset.
In this article we will explore the different ways in SAS to identify and remove duplicate data from a dataset.
- PROC SORT Procedure
- Match Merge
- PROC SQL – Group By and Delete Statement
1. Delete Duplicates Using PROC SORT Procedure
Proc sort procedure is used to sort the data based on one more variable specified in the BY statement. There are two options: NODUPKEY and NODUP (NODUPRECS), which can be used to sort the data, identify duplicate rows and delete it from the dataset.
I have already written separate articles explaining the difference between nodupkey and nodup, 10+ examples of proc sort procedure.
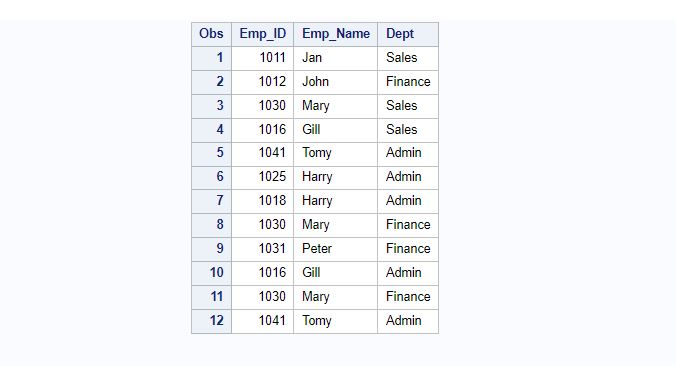
The following sample dataset will be used to demonstrate different ways to identify and delete duplicates in SAS.
/* create a dataset */
data Employee;
input Emp_ID 4. Emp_Name $ Dept $;
datalines;
1011 Jan Sales
1012 John Finance
1030 Mary Sales
1016 Gill Sales
1041 Tomy Admin
1025 Harry Admin
1018 Harry Admin
1030 Mary Finance
1031 Peter Finance
1016 Gill Admin
1030 Mary Finance
1041 Tomy Admin
;
run;
/* view dataset */
proc print data=Employee;
run;
The PROC SORT in SAS
The proc sort procedure gives you the option to create a new dataset to store duplicate rows which can be used later for further analysis. It can be created using dupout=<dataset name> option in proc sort.
You either delete duplicates and update the original dataset or create a separate dataset without duplicates without modifying the original dataset. It can be done using the OUT=<dataset name> option.
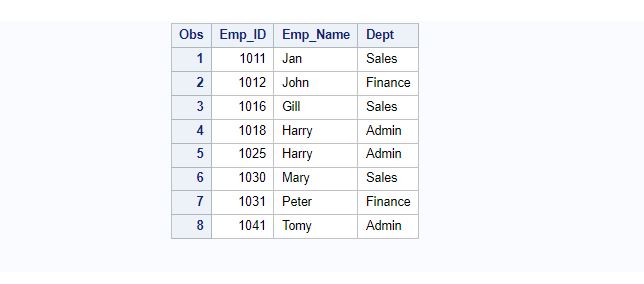
The following code demonstrates how to identify and delete duplicate rows using the nodupkey option in the proc sort procedure.
/* proc sort: create dup data and no dup data */
proc sort data=Employee out=no_dup_data nodupkey dupout=dup_data;
by Emp_ID;
run;
/* view dataset with no duplicate rows */
proc print data=no_dup_data;
run;
Delete Duplicates Directly From The Original Dataset:
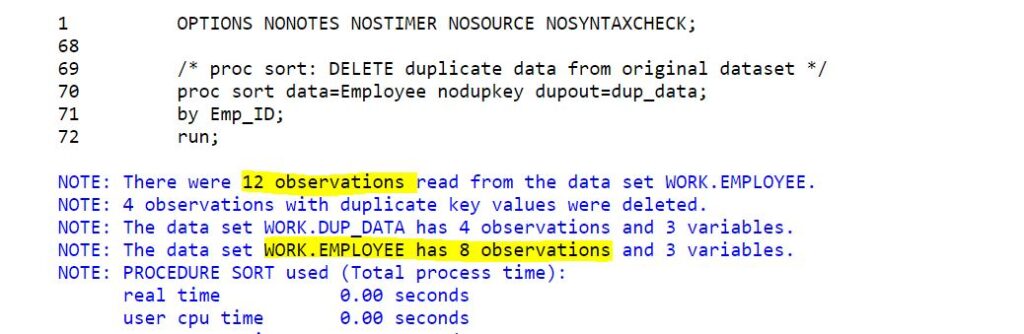
In case if you’re fully confident and don’t want to create a separate dataset with no duplicates but want to delete duplicates directly from the original dataset itself then don’t use the out=<option>.
If you don’t mention OUT= option in proc sort, it means the original dataset will be updated.
/* proc sort: DELETE duplicate data from original dataset */
proc sort data=Employee nodupkey dupout=dup_data;
by Emp_ID;
run;
Remove Duplicates from ALL the columns
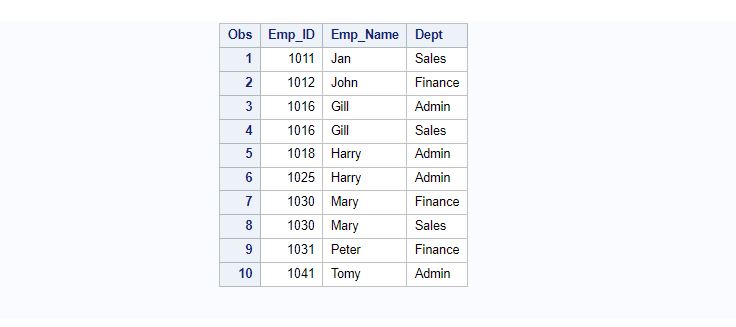
You can easily have a check on the entire dataset across the variables and delete duplicate rows if there are any using proc sort with _ALL_ after BY statement.
In the following example duplicates will be removed from the Employee dataset based on all the variables present in the dataset. A new dataset will be created to store duplicate data and Employee dataset but without duplicate.
PS- As we have mentioned out= option, it will not modify the original Employee dataset.
/* PROC SORT - Remove Duplicates from ALL the columns */
proc sort data=Employee out=no_dup_data nodupkey dupout=dup_data;
by _ALL_;
run;
/* view dataset with no duplicate rows */
proc print data=no_dup_data;
run;
2. Delete Duplicates Using Data Step: First. And Last. Variables
The FIRST. and Last. functions can be used to identify first or last observations by group in a SAS dataset.
- First.Variable: It assigns value 1 to the first observation and 0 to the rest of the observations within the group in a SAS dataset.
- Last.Variables: It assigns value 1 to the last observation and 0 to the rest of the observations within the group in a SAS dataset.
These are also called indicators to identify first and last observations in the group.
PLEASE NOTE: The SAS dataset must be sorted on the BY group before using the first. and last. functions.
The same above sample dataset Employee will be used to demonstrate how to use it first. And last. functions to identify duplicates and delete it from the dataset.
The below code creates two new datasets.
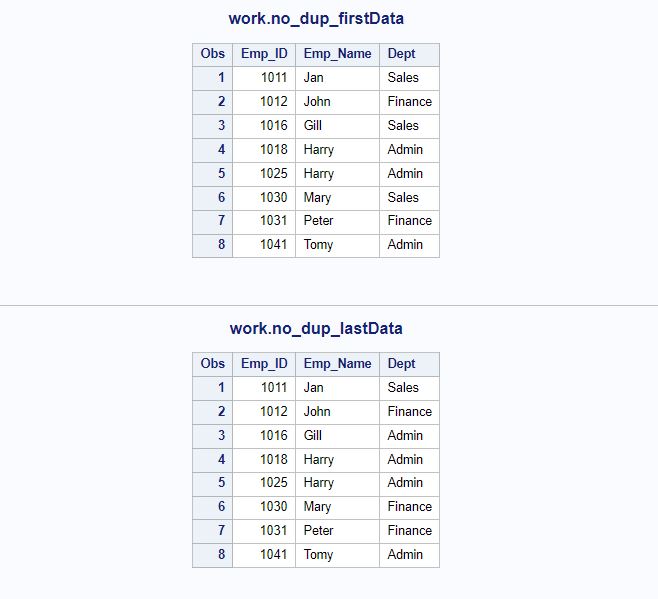
- The first one, work.no_dup_firstData created keeping the first occurrence of Emp_Id and deleted remaining rows from the group.
- And the second one, work.no_dup_lastData created keeping the last occurrence of Emp_Id and deleted remaining rows from the group.
Preparation: sort data on BY variable
/* sort dataset based on Emp_ID */
proc sort data=Employee;
by Emp_ID;
run;
/*view sorted dataset */
proc print data=Employee; run;
Remove Duplicates In SAS
/* keeps only first and last observations */
data no_dup_firstData no_dup_lastData;
set Employee;
by Emp_ID;
if first.Emp_ID=1 then output no_dup_firstData;
if last.Emp_ID=1 then output no_dup_lastData;
run;
/* view dataset */
proc print data=no_dup_firstData;
title 'work.no_dup_firstData';
run;
proc print data=no_dup_lastData;
title 'work.no_dup_lastData';
run;
Remove Duplicates From The Original Dataset
In case if you’re confident and want to re-write the original dataset by removing duplicates then you can do so here without creating a separate dataset.
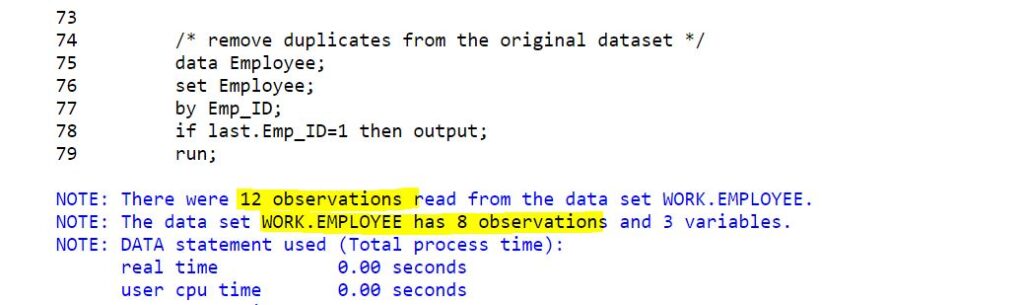
In the below example delete the duplicates based on last.Emp_ID. It means you’ll only keep the last observation from the group and delete remaining observations.
You’ll not create a new dataset but you’ll update the original dataset Employee.
/* sort dataset based on Emp_ID */
proc sort data=Employee;
by Emp_ID;
run;
/* remove duplicates from the original dataset */
data Employee;
set Employee;
by Emp_ID;
if last.Emp_ID=1 then output;
run;
/* view dataset */
proc print data=Employee;
run;
BONUS EXAMPLE:
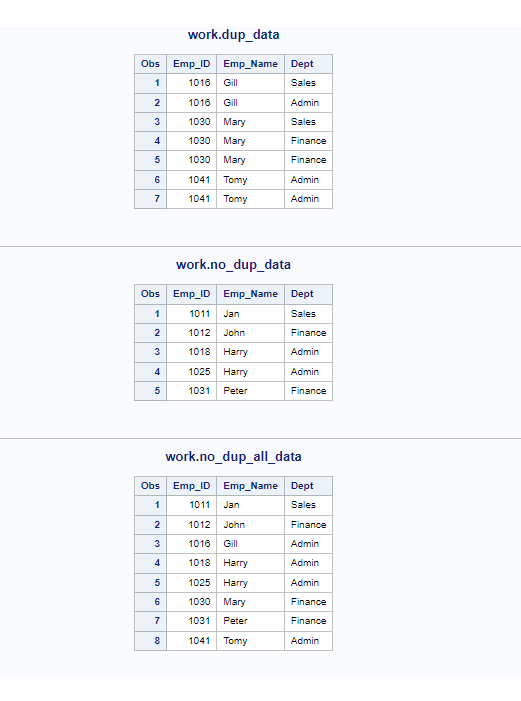
This example demonstartes how to create multiple datasets such as dup_data, no_dup_data, no_dup_all_data datasets.
- dup_data: It stores duplicate rows.
- no_dup_data: It stores Non-duplicate rows.
- no_dup_all_data: It stores all the unique rows. The duplicate rows handled by keeping only first row whenever it finds duplicates.
/* sort dataset based on Emp_ID */
proc sort data=Employee;
by Emp_ID;
run;
/* Creates dup data, no dup, no dup all datasets */
data dup_data no_dup_data no_dup_all_data;
set Employee;
by Emp_ID;
if (first.Emp_ID=1 and last.Emp_ID=1) then
output no_dup_data;
if not (first.Emp_ID=1 and last.Emp_ID=1) then
output dup_data;
if last.Emp_ID=1 then
output no_dup_all_data;
run;
/* view dataset */
proc print data=dup_data; title 'work.dup_data';
run;
proc print data=no_dup_data; title 'work.no_dup_data';
run;
proc print data=no_dup_all_data; title 'work.no_dup_all_data';
run;
3. Delete Duplicates Using PROC SQL – Group by and DELETE Statement
This is a traditional method being used to identify and delete duplicates BY grouping one or more variables. It’s a two step process.
- The first one is to identify the duplicates using proc sql, distinct and group by.
- The second one is to use identified duplicate data to delete rows from the original dataset using subquery.
The following code creates a new dataset with duplicate rows from the Employee dataset.
/* Find duplicate rows */
proc sql;
create table dupdata as select distinct Emp_ID, count(*) as cnt
from Employee group by Emp_ID;
run;
/* view dataset */
proc print data=dupdata; run;
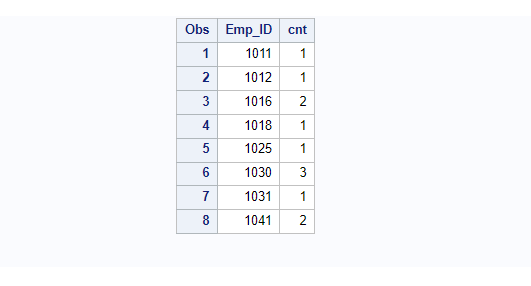
Now you can use the same duplicate data to delete the duplicate rows from the original dataset Employee using proc sql subquery.
/* Delete duplicate rows */
proc sql;
delete from Employee
where Emp_ID in (select Emp_ID from dupdata where cnt>=2);
quit;
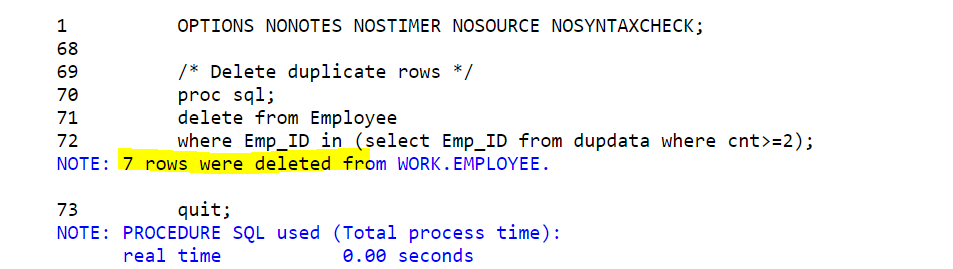
How To Find and Delete Duplicates Based on Multiple Variables
Finding and deleting duplicates based on multiple variables can also be done through proc sql procedure.
You can use the exact same procedure explained above by just adding variable names in the select and group by statement.
Here’s how: Let’s identify the duplicates considering two variables: Emp_ID and Dept.
/* Find duplicate rows based on multiple columns*/
proc sql;
create table dupdata as select distinct Emp_ID, Dept, count(*) as cnt
from Employee group by Emp_ID, Dept;
run;
/* view dataset */
proc print data=dupdata; run;
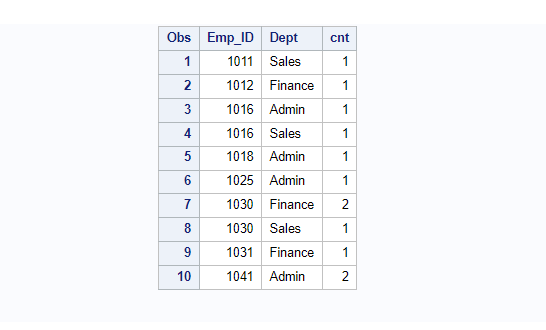
/* Delete duplicate rows based on multiple key columns*/
proc sql;
delete from Employee
where Emp_ID in (select Emp_ID from dupdata where cnt>=2) and
Dept in (select Dept from dupdata where cnt>=2);
quit;
/* view dataset */
proc print data=Employee; run;
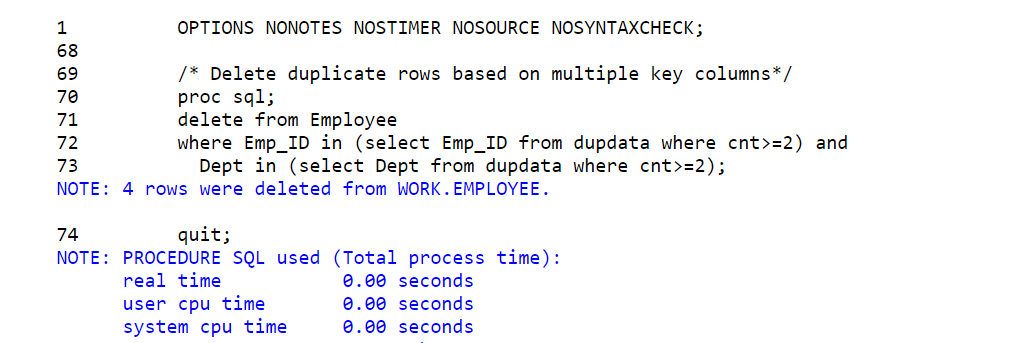
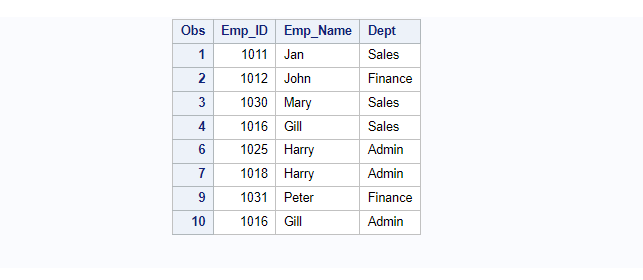
If you observe the above result, due to proc sql- delete operation the Obs is not in sequence. Don’t get confuse with the Obs numbering. The seq doesn’t get reinitialise when you use proc print procedure after DELETE operation.
FAQ
You can use the PROC SORT procedure with the dupout option to identify duplicates in SAS.
The dupout option creates a new dataset and keeps only the duplicate observations of the original dataset.
When using PROC SORT in SAS, you can use the dupout option to output duplicate observations.
You can specify nodupkey or noduprecs as well to specify if the duplicates should be identified with BY values or for the entire observation.
To remove identical rows from a SAS dataset with the PROC SORT procedure, you use the NODUPKEY keyword and the BY _ALL_ statement.
The result of this code is identical to the PROC SQL procedure discussed above.